Day 11 in the #vDM30in30
Image Source: http://www.slideshare.net/PuppetLabs/the-puppet-master-on-the-jvm-puppetconf-2014
There is an oft-repeated joke that says that there are two hard things in computer science: cache invalidation, naming things, and off-by-one errors.
We’re going to talk about caching with puppet-server.
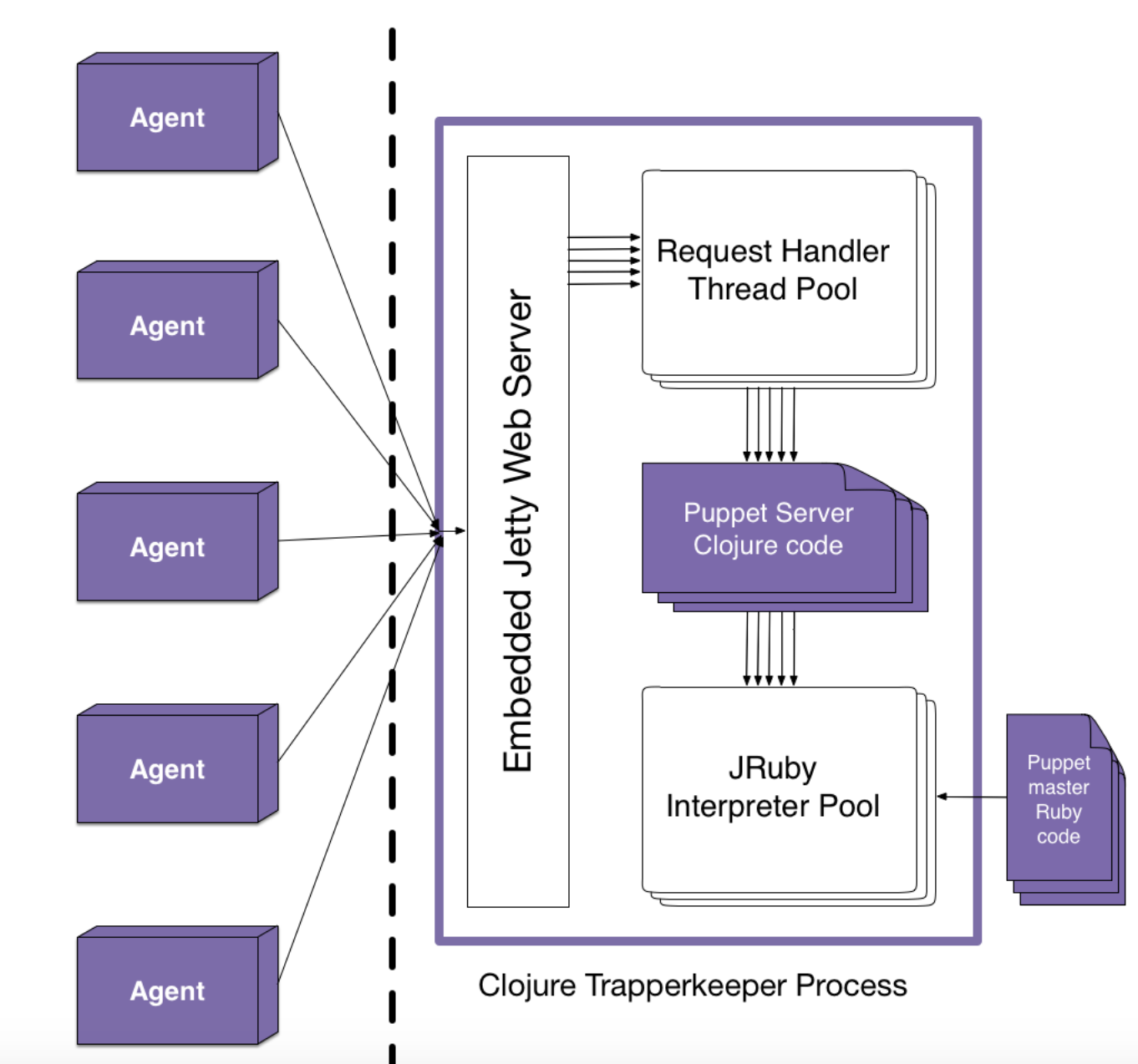
What is Puppet Server
puppetserver is a replacement for the previous ruby and passenger engine (aka puppetmasterd)
So puppetmaster was the old puppet server, puppetserver is now the current puppet-master.
Remember, naming is hard!
It can be a little confusing for people used to the old ways, as it’s moved from the Ruby stack to JRuby/Clojure, and there one of the things that can come up is the differences with caching.
This change brought with it huge performance increases, as Ruby and Passenger are hard to scale, whereas since both Clojure and JRuby run in the JVM, which you can generally through a load of memory at with heap settings and you’re good to go.
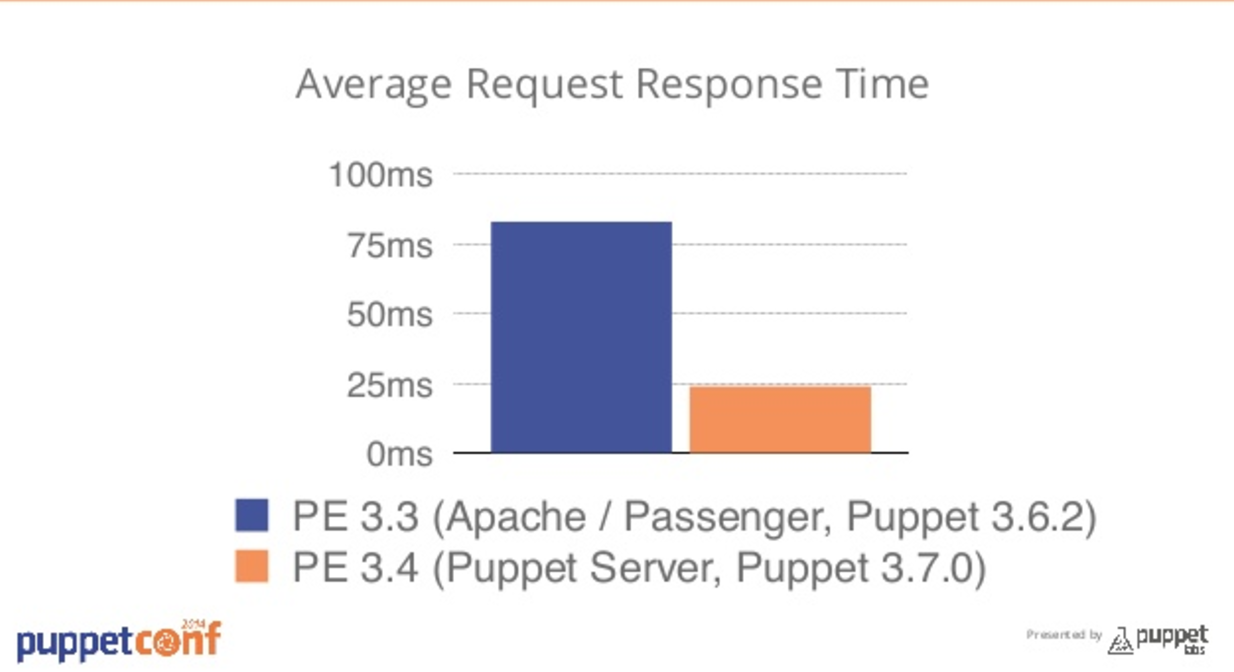
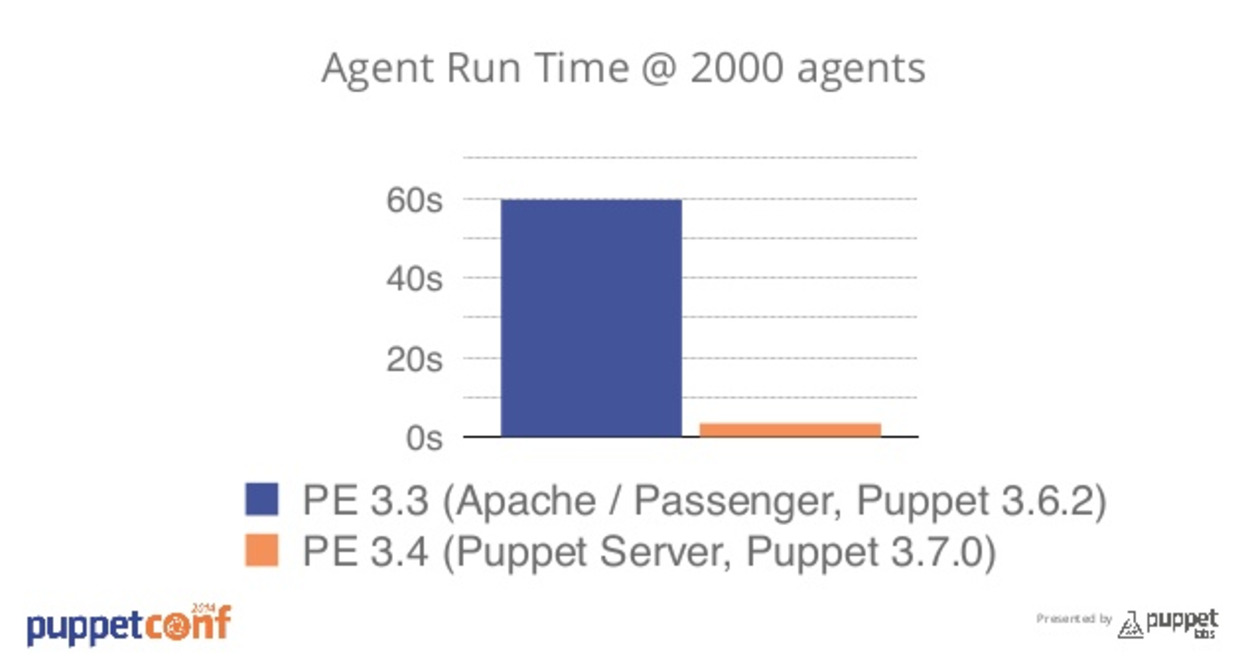
The manifest caching problem
I was working with a customer who was on and older version of Puppet (3.3), but had upgraded to a newer release that featured puppetserver instead of passenger.
They didn’t have local VMs, so their old code deployment process was a dedicated compile master, which they then checked git code out and symlinked to the environment folder.
You would then point a canary node to the dedicated compile master, make a change locally to modules and manifests from their local copy of the code on the master, then run an agent test run, pointing to the compile master. Any change in the code on the master would be reflected immediately in catalogs.
(It should be noted, this is not their main process, they have a full Bitbucket, pull-request with review workflow, code manager, file sync etc. process for actual deployments with code review and so on. But for a change that they could quickly test against an existing system or quickly hack on an idea, it was ok)
What was confusing was that these local changes weren’t being reflected when the agent checked in, only when the puppetserver was completely restarted.
Environment caching
This because of the environment timeout, changes would not be reflected until the cache was specifically cleared by an API request.
This is set by the environmenttimeout option.
From the docs:
How long the Puppet master should cache data it loads from an environment. This setting can be a time interval in seconds (30 or 30s), minutes (30m), hours (6h), days (2d), or years (5y). A value of 0 will disable caching. This setting can also be set to unlimited, which will cache environments until the master is restarted or told to refresh the cache.
You should change this setting once your Puppet deployment is doing non-trivial work. We chose the default value of 0 because it lets new users update their code without any extra steps, but it lowers the performance of your Puppet master.
https://docs.puppet.com/puppet/4.8/reference/configuration.html#environmenttimeout
The environmenttimeout of 0 is less performant, as the master recompiles catalogs every time an agent checks in, but it’s more expected behaviour.
Why unlimited?
When doing a proper git deployment process, such as Puppet Enterprises code manager, r10k or some over version control workflow, the environment timeout should be set to unlimited.
This is because there’s no point recompiling catalogs, checking for changes to code when we know the code shouldn’t have been changed without a proper deploy process. The cache would be manually refreshed after the deployment process has occurred, such as a post recovery hook in r10k or automatically with code manager.
The endpoint is documented here, and is automatically done with Puppet Enterprise Code Manager, but can be easily configured with an r10k post-deploy hook.
Hopefully that clears things up a bit around environment caching with puppetserver!